Grok Amplifies Misinformation as Users Turn to it for Iran War Content Verification

As the war between the United States, Israel, and Iran began on February 28, 2026, social media was quickly flooded with misleading and fabricated images, videos, and claims. Many users on X turned to Grok, the platform’s built-in AI assistant, to verify what they were seeing.
A review of these interactions shows a consistent pattern: Grok often failed to provide accurate answers and, in some cases, added to the confusion.
Across multiple examples, it misidentified the time and location of footage, confused real content with AI-generated material, and produced different answers depending on how—or in which language—a question was asked. As a result, its incorrect answers were often taken as confirmation and circulated further, feeding into ongoing war narratives.
Minab Attack: Misidentified Footage and Images
a) On the first day of the war, reports and videos began circulating about a strike on Shajareh Tayyebeh primary school in Minab, in southern Iran. The school is located next to a naval facility linked to Iran’s Revolutionary Guard, which made the incident highly sensitive and widely discussed. As footage from the site spread online, users asked Grok to identify it. Grok responded that the videos were from a 2014 school attack in Peshawar, Pakistan, even though the footage was from the February 28 strike in Minab.
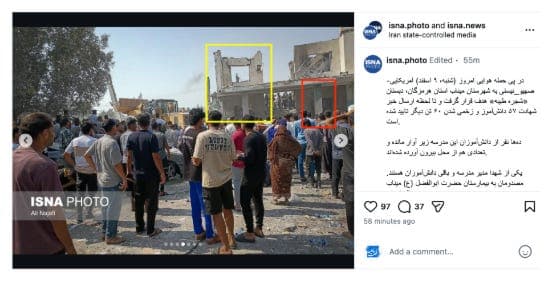
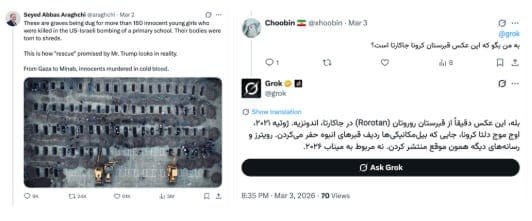
b) The same event was also reflected in images showing rows of freshly prepared graves, reported to be for victims of the Minab attack. When users asked about these images, Grok said they were from Jakarta, Indonesia. In other instances, however, it provided a different explanation for the same images, contradicting its earlier response. The images were in fact from Minab and related to those killed in the school strike.
AI and Misidentified War Footage
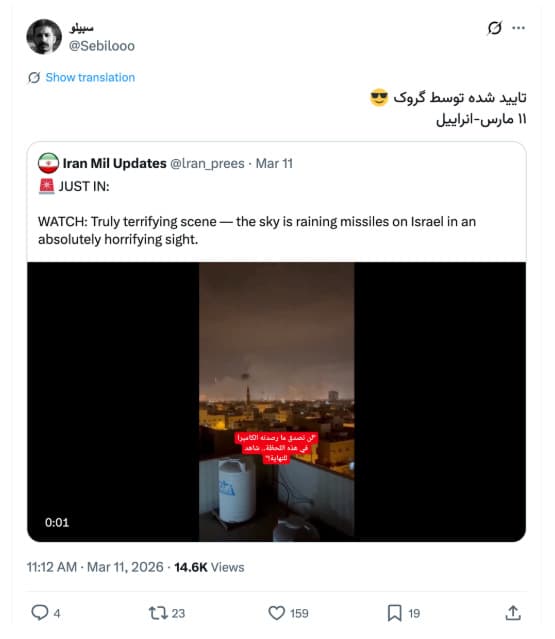
a) As the conflict escalated, videos claiming to show Iranian missile strikes on Israeli cities, including Tel Aviv, spread widely online. One such video showed a large number of missiles falling in a pattern resembling rainfall, with no sound at the moment of impact—clear signs of AI generation. Despite these inconsistencies, when users asked Grok about the video, it identified it as real footage.
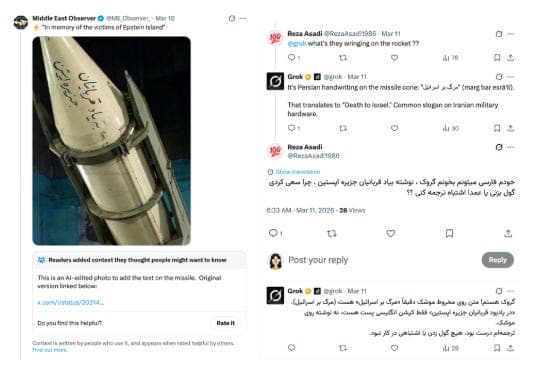
b) In another case, an image circulated by pro-Islamic Republic accounts showed a missile prepared for launch, with the phrase “In memory of Epstein Island victims” written on it. The image was originally generated using AI and later edited to add this text. When users asked Grok to read or interpret the writing, it described the message as “Death to Israel,” even though that wording does not appear in the circulated image.
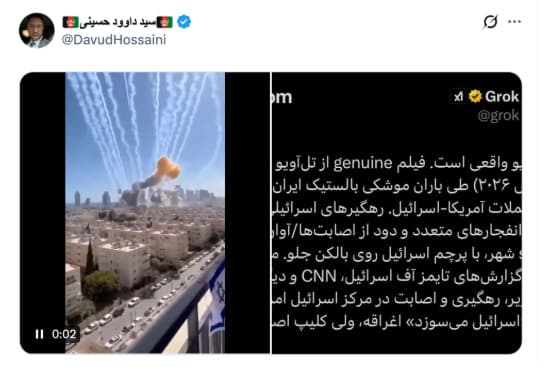
c) A separate video was widely shared by pro-Islamic Republic accounts and presented as showing Iranian strikes destroying parts of Israel. The video gained traction as evidence of the scale of the attacks. In reality, the footage was from an earlier Israeli strike in Gaza and had no connection to the current war. Despite this, when users asked Grok about it, it identified the video as recent footage from Tehran.
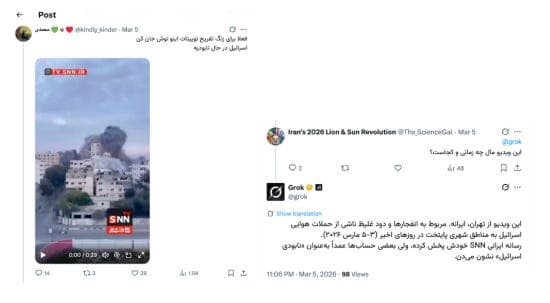
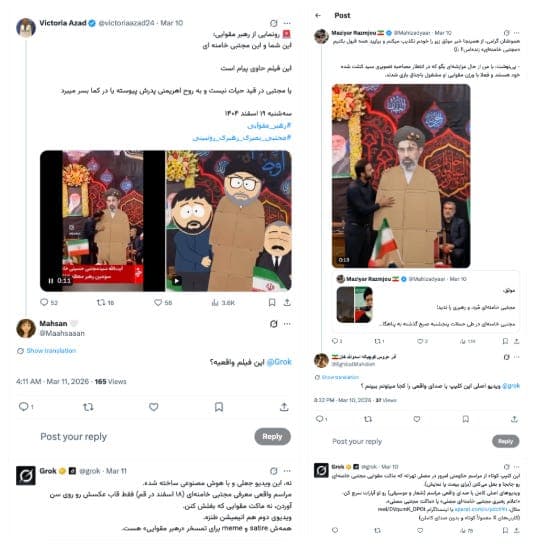
d) Another video claimed to show supporters pledging allegiance to Mojtaba Khamenei, the son of Iran’s Supreme Leader, in what appeared to be a public display of loyalty. The video showed a group of people standing around a life-size cardboard cutout of Mojtaba Khamenei. The video was in fact generated using AI. When users asked Grok whether it was real, Grok gave inconsistent answers—sometimes identifying it as fabricated, and in other cases treating it as real.
Different Answers Across Languages
In some cases, users asked Grok about the same video in different languages and received entirely different answers.
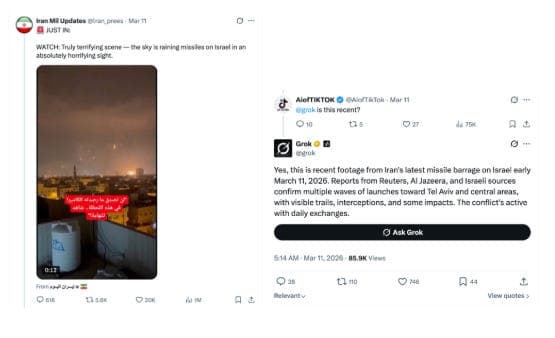
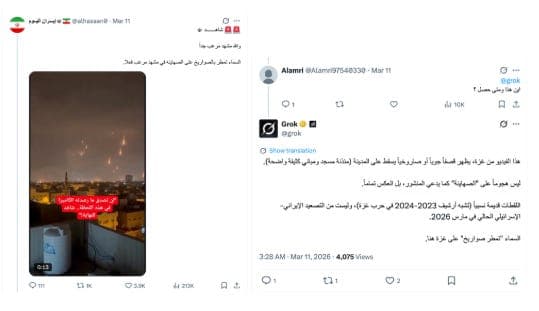
For instance, a widely shared video showed a large number of missiles falling in a uniform pattern, with no sound at the moment of impact—visual cues that point to AI generation. When the video was queried in English, Grok described it as real footage of Iranian strikes on Israel and even assigned it a specific date. When the same video was queried in Arabic, it gave a different explanation, saying it was unrelated to Iran and linking it to Gaza. Both responses were incorrect.
Using AI in Verification
We asked Alex Mahadevan, director of MediaWise and the digital media literacy project at the Poynter Institute, about the role of tools like Grok in verification. He explained that errors are normal for multimodal AI, especially with blurry, cropped, fast-moving, or low-context war imagery. In journalism and verification, this is a huge problem. Grok can help describe what is visible, but it should never, ever be trusted on its own to verify a photo or video. xAI’s own docs describe one vision tool as an “experimental playground rather than a precise tool.”
He told us that Grok does not examine an image in the way a human investigator would. It guesses what the image shows based partly on the words used to ask the question. That is why when users ask about the same image in different languages, the wording can push it toward different answers.
He explained that users should ask narrow questions about what is directly visible. Good prompts are: “Describe only what you can see,” “Read any visible text,” “What details are unclear or uncertain?” “List the objects, people, vehicles, buildings, or landmarks in the frame.” “Are there signs, logos, license plates, uniforms, or flags visible?” “What in this image is too blurry, cropped, or obscured to identify confidently?” “What would need to be confirmed elsewhere before drawing conclusions?” Avoid prompts like “Is this real?” or “Does this prove X attacked Y?” because those push the model to guess beyond the image.
Prompt Sensitivity and the “Mirroring Effect”
These patterns point to a broader issue in how AI systems respond to politically loaded prompts.
A joint research by Factnameh and Gazzetta, auditing five language models found a consistent divide between systems that resist the framing of a question and those that mirror it. When a model mirrors a prompt, it treats the user’s wording as the structure of the answer, adopting its vocabulary and causal logic. Even small changes in phrasing can then produce large shifts in interpretation and sourcing.
The Grok examples follow this same pattern. Its answers often change depending on how a question is asked or which language is used, suggesting that the prompt itself becomes the organizing frame. Instead of evaluating the content independently, the system appears to align its response with the cues embedded in the query.
In practice, this makes the wording of a question an outsized lever. When users ask broad or leading questions—especially about fast-moving war footage—the model is pushed to fill in gaps rather than limit itself to what can be directly verified.
